正则表达式
推荐链接
学习思路
- [x] 先使用菜鸟教程简单的学习
- [ ] 再找一个高级语法的深入学习
- [x] 使用2-3个网站进行练习
- [x] 每日练习一道正则
- [x] 掌握shell下常用命令使用正则:
grep
- [x] 掌握shell下常用命令使用正则:
测试文本
Fixed-asset investment — a gauge of expenditures on items including infrastructure, property and machinery and equipment — increased by 5.5 percent during the two-month period, compared with a 5.1 percent rise for the whole of 2022.简单学习笔记(菜鸟教程)
匹配普通字符
[ABC][^A][a-zA-Z].注意是单个点,非“[.]”,匹配除换行(\n、\r)外的所有字符,等同[^\r\n]\s:匹配所有的空白字符,包括换行。\S:匹配所有的非空白字符。[\s\S]就是匹配所有。\w:匹配字母,数字,下划线,等同:[a-zA-Z0-9_]
非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 返回由x指定的控制字符,一般是ascii,测试并没有理解其作用 |
| \f | 匹配一个换页符。等于\x0c和\cL |
| \n | 匹配一个换行符。等于\x0a和\cJ |
| \r | 匹配一个回车符。等价于\x0d,\cM |
| \s | 匹配任何空白字符,包括空格制表符,换页符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符。 |
特殊字符
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串结尾位置。要匹$使用\$ |
| () | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用 |
| * | 匹配前面的子表达式零次或者多次 |
| + | 匹配前面的子表达式一次或者多次。 |
| ? | 匹配前面的子表达式零次或者一次。或指明一个非贪婪限定符。 |
| \ | |
| ^ | 匹配字符串开始的位置,在方括号中使用为非,不接受该字符串。 |
| | | 或 |
限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式0次或者多次,例如zo*能匹配z以及zoo。等价于 |
| + | 匹配前面的子表达式一次或者多次。例如,zo+能匹配zo与zoo。等价于 |
| ? | 匹配前面的子表达式零次或者一次。例如,do(es)?可以匹配do,does,doxy中的do,does。等价于 |
n是一个非负整数。匹配确定的n次。例如,o{2}不能匹配Bob中的o,但可以匹配food中的o。 | |
n是一个非负整数。至少匹配n次。例如,o{2}不能匹配Bob中的o,但可以匹配fooooood中的所有o。 | |
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 fooooood 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
**技巧:**通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从"贪婪"表达式转换为"非贪婪"表达式或者最小匹配。(得多练练)
定位符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
**注意:**不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^*·之类的表达式。若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆。若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。
选择
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n是一个数字,表示第 n 个捕获组的内容)。
这里如下图:

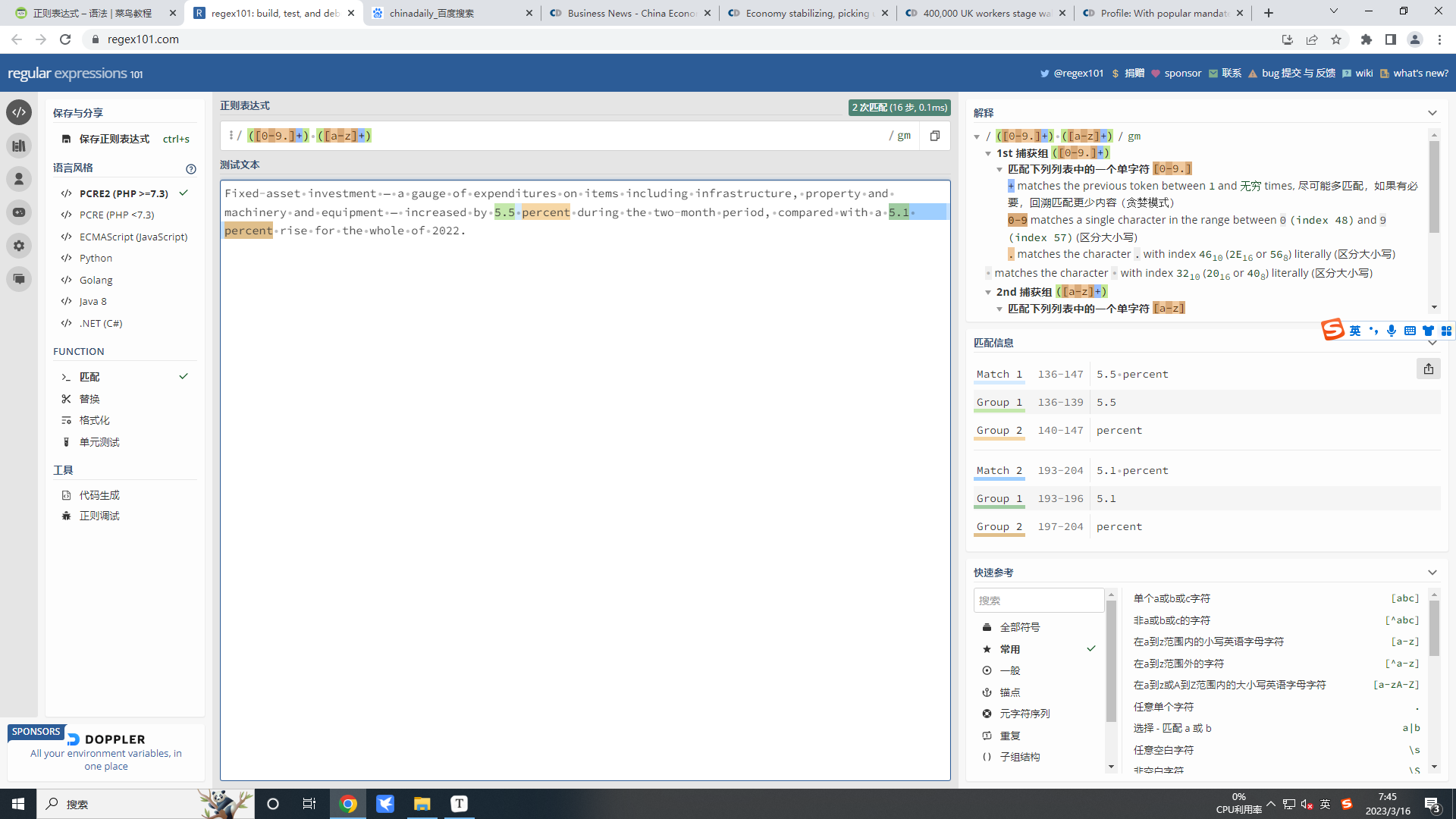
**注意:**圆括号会有一个副作用,使得相关的匹配会被缓存,此时可以使用?:(非捕获元)来消除盖副作用。
非捕获元
?:
+ (?:pattern)
匹配 pattern 但不获取匹配结果。?= 与 ?<=
+ exp1(?=exp2)
查找exp2前面的exp1
+ (?<=exp2)exp1
查找exp2后面的exp1?! 与 ?<!
+ exp1(?!exp2)
查找后面不是exp2的exp1
+ (?<!exp2)exp1
查找前面不是exp2的exp1反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
- 实例1
查找源:"Is is the cost of of gasoline going up up";
正则表达式:\b([a-z]+)\1\b
结果:Is is,of of,up up- 实例2
查找源:"https://www.runoob.com:80/html/html-tutorial.html";
正则表达式:(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)
结果:
https
www.runoob.com
:80
/html/html-tutorial.html
解释:这是一个解析网络各部分数据的一个正则表达式其他
\d: 阿拉伯数字
\D:非阿拉伯数字
简单的正则练习
- 使用
https://www.codejiaonang.com/#/course/regex_chapter1/0/0来练习。- 当前学习到第五课
- 当前学习到第八课
- 学习到匹配电话号码(不包括该节)
- 完成初级挑战
在Linux常用命令中使用正则
命令的官方说明(英文)摘录在
附件/Linux/Linux常用命令原文档(英文).md中,这里使用简略版(中文)。
grep
grep支持3种正则表达式语法:Basic,Extended,Perl。如果没有设置
grep的正则表达式类型,默认情况下就是Basic。如果要使用Extended,可使用:grep -E
Bsic(基本语法)
grep支持基本的正则语法,它们如下:
^,$: 行开始结束
.: 任意非空字符
[]: 指定范围内的字符
[^]: 非指定范围内的字符
<: 单词的开始 ,如果没有用非扩展,注意加'\'
>: 单词的结束 ,如果没有用非扩展,注意加'\'
{n}: 重复n次 ,如果没有用非扩展,注意加'\'
{n,}: 至少n次 ,如果没有用非扩展,注意加'\'
{n,m}: 至少n次 ,如果没有用非扩展,注意加'\'
\w,\W: 单个字符,非字符
\b: 单词边界
\: 转义
*: 0次或者多次实例:
# 获取非空行数据
grep -vn '^$' /etc/samba/smb.conf
# 这里'^$'表示空行,-v取反
# 匹配以wh开头的字符,注意使用'\<'
grep -n '\<wh' /etc/samba/smb.conf
# 匹配userxxxx,注意使用'\{'与'\}'
grep -n 'user\w\{0,6\}' /etc/samba/smb.conf
# 可匹配:user users username
# 匹配userxxxx
grep -n 'users*' /etc/samba/smb.conf
# 可匹配:user users
#
grep -n 'user[^n]' /etc/samba/smb.conf
#可匹配:user users user',不可匹配usernExtend(扩展语法)
grep -E或者命令egrep
+: 贪婪符
?: 非贪婪符
|: 或
(): 分组引号
事实上, 对字符串的解析是由shell完成再传递给
grep,因此参考shell的特殊字符,以正确使用引号来确保表达正确,在此仍做简单说明。
' '单引号,字符串保持原样输出
" "双引号,字符串中的' ' ,$, \ 等特殊字符会被shell解释替换后,再传递给grep对普通的字符串(没有特殊字符和空格的字符串)也能够不加引号,直接搜索。
如:
[ade@h test]$ grep -n $HOME regular.txt
2:/home/ade
[ade@h test]$ grep -n "$HOME" regular.txt
2:/home/ade
[ade@h test]$ grep -n '$HOME' regular.txt
5:$HOME
[ade@h test]$ grep -n "\$HOME" regular.txt
5:$HOME贡献者
 Px
Px